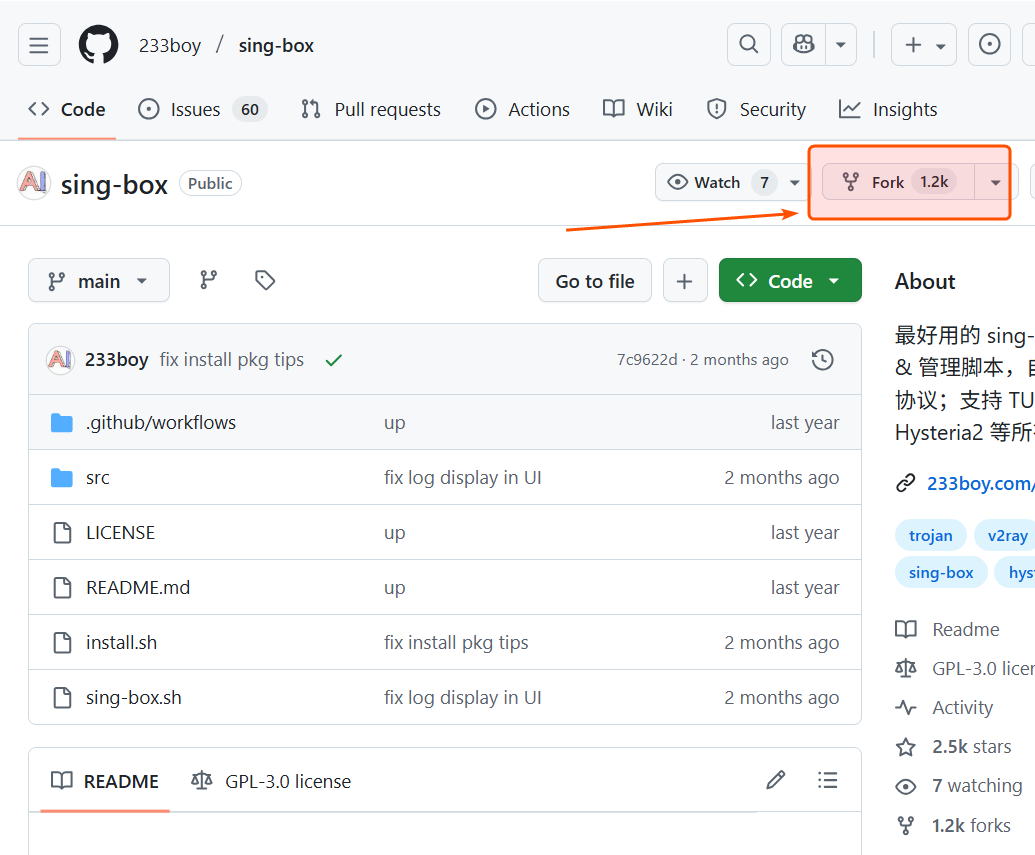
在NaiveProxy上使用IP的TLS证书

前言 群友问能否不使用域名搭NaiveProxy 正在我准备回复 "No" 的时候, 我想到了最近不是Caddy支持了IP证书嘛, 能不能结合在一起玩玩? 思路 用 现成的脚本 生成配置文件和各种参数. 结果是这样的 # _naive_config_begin_ { order forward_proxy first } :2083, np.icdyct.dpdns.org:2083 { tls e16d9cb045d7@gmail.com forward_proxy { basic_auth 864aeebd36be 864aeebd36be hide_ip hide_via probe_resistance } file_server { root /var/www/xkcdpw-html } } # _naive_config_end_ 最近Caddy支持IP证书的语法 是这样的 74.48.9.95 { tls { issuer acme { profile shortlived } } file_server { root /var/www/xkcdpw-html } } 融合一下, 结果是这样的 # _naive_config_begin_ { order forward_proxy first } :2083 74.48.9.95:2083 { tls { issuer acme { profile shortlived } } forward_proxy { basic_auth 864aeebd36be 864aeebd36be ...